Bevor das User-Journey Modell (h2o Machine Learning: Individuelle Vorhersage für die „next best activity“ – Teil 1) weiter verfeinert wird, ist ein Modell für die User Interaktion auf der Webseite sinnvoll. Dabei geht es um die Bewertung des Einflusses von Micro-Conversions auf die eigentliche Conversion. Ist beispielsweise die Eigenschaft des Users den Newsletter abonniert zu haben, für die Vorhersage eines Kaufs wichtig.
Random Forest Modell
Hierfür setze ich auf wieder auf h2o, nutze allerdings Random Forest Modelle statt Neuronalen Netzwerken, wie im ersten Teil. Bei einem Random Forest Modell werden Entscheidungsbäume zusammengebaut. Reihenfolge, Ausprägung und Gewichtung der Eingangsvariablen im Entscheidungsbaum werden dabei zufällig zusammengefügt um die Ausgabevariablen vorherzusagen. Da parallel eine Vielzahl von Bäumen gebaut werden, werden diese gegeneinander getestet und Baum mit der geringsten Fehlerquote als Modell genutzt.
In unserem Beispiel wurden sechs Microconversions identifiziert: Promotionklick, Merkliste genutzt, Warenkorb genutzt, Registrierung, Newsletterabonnement, Chat-Funktion genutzt. Bei der Bewertung dieser Microconversions ist weder die Reihenfolge noch die Interaktion der Microconversions untereinander wichtig. Das Modell soll lediglich die Aussage treffen können, wie wichtig das Vorkommen einer Microconversion in Bezug auf die Macroconversion ist.
In den Daten zur Modellbildung ist dann jede Microconversion in jeweils einer Spalte (C1 bis C6) diskret mit 0 (false) oder 1 (true) repräsentiert. Hinzukommt eine Spalte für die Macroconversion, die wieder Buyer oder Non-Buyer angibt. Die Daten liegen wieder im CSV Format vor:

h2o Start und Daten einlesen
Die Daten werden eingelesen und in Trainings- sowie Testdaten gesplittet. Zudem wird wieder die Ausgabevariable in Y und die Eingangsvariablen in x definiert.
libary(h2o)
h2o.init()
data<-h2o.importFile("microconv.txt")
datasplit<-h2o.splitFrame(data,0.8)
modell<-parts[[0]]
validation<-parts[[1]]
Y<-C7
x<-setdiff(names(modell), y)
Danach werden die Bäume aufgebaut:
rf<-h2o.randomForest(x,Y,train,nfolds=150, model_id="RFdefault")
(Quellcode basierend / mehr Informationen: https://www.rdocumentation.org/packages/h2o/versions/2.4.3.11/topics/h2o.randomForest)

Bei den Trainingsdaten liefert der Siegerbaum bei der Vorhersage brauchbare Ergebnisse. Auch bei der Anwendung der Testdaten auf das Modell sind die Ergebnisse zufriedenstellend.
h2o.performance(rf,test)

Eine Teilvisualisieung des Siegerbaums verdeutlicht nochmal die Methodik des Random Forest Modells:
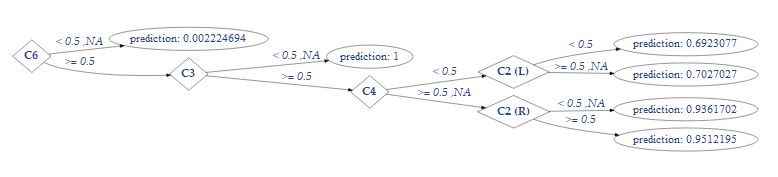
Um nun den Stellenwert einer Microconversion zu beurteilen, kann die Funktion h2o.varimp

bzw. h2o.varimp_plot genutzt werden.

Die Ausgabe zeigt, wie eine Microconverion (C1 bis C6) im Entscheidungsbaum gewichtet wird, um die Macroconversion (Buyer, Npn-Buyer) vorherzusagen. In diesem Beispiel ist das Newsletterabonnement (C6) und der Promotionklick (C1) sehr wichtig.
Diese Erkenntnis kann beispielsweise zur Optimierung des Media-Budgets oder auch zur Usability-Optimierung genutzt werden. Im dritten Teil bringen wir On- und Off-Site Daten zusammen.
2 thoughts on “h2o Machine Learning: Stellenwert der Microconversion in der User Journey – Teil 2”
Comments are closed.