Die Erfassung der User-Journey kann nicht nur zur Attribution von Conversions und Budgetallokation genutzt werden. Insbesondere die Vorhersage des nächsten Kontaktpunktes in der individuellen User-Journey ist wertvoll, um die Wahrscheinlichkeit einer Conversion zu erhöhen. Neuronale Netzwerke eignen sich hierfür. h2o liefert die passende Werkzeuge.
Vorhersage-Modell trainieren
Als Erstes benötigen wir ein Datenset für das Training des Neuronalen Netzwerks. Um das Modell übersichtlich zu halten, beschränken wir uns auf max. 4 Kontaktpunkte mit Marketing-Kanälen. In dem Model existieren folgende Marketing-Kanälen:
- Mailing – Postversand von Katalog
- Social – Social Media Posts
- Search – Suchmaschinen
- Newsletter – Versand von Newslettern
- Voucher – Verteilung von Gutscheinen
- Display – Bannerwerbung
- None – Kein Kontaktpunkt (wird zum Auffüllen verwendet, falls kein Kontaktpunkt vorhanden)
Die User-Journeys werden dann den Kategorien „Buyer“ (wenn die User-Journey zu einem Verkauf führt) und „Non-Buyer“ (wenn kein Kauf durch die User-Journey initiiert wurde). Damit ergibt sich folgendes Schema für die Trainingsdaten:
| 1. Interaction | 2. Interaction | 3. Interaction | 4. Interaction | Classification |
| Social | Voucher | Social | Mailing | Buyer |
| Social | Voucher | Search | Newsletter | Non-Buyer |
| Search | Newsletter | Social | Search | Buyer |
| Display | Newsletter | Newsletter | None | Buyer |
| Display | Display | Newsletter | Search | Non-Buyer |
Für die Modellbildung werden insgesamt 2100 User-Journeys (1176 Non-Buyer, 924 Buyer) verwendet. Für eine Produktivnutzung sollten allerdings deutlich mehr Daten vorliegen, da sich nicht auf die 4 Kontaktpunkte und oftmals auch nicht auf die aufgezählten Marketing-Kanäle beschränkt werden kann.
Nun müssen diese Daten in ein Modell umgewandelt werden. Dazu wird h2o, ein AI Framework für R und Python, genutzt. In diesem Fall verwende ich R, R Studio und die Daten im CSV Format.

h2o installieren und starten
install.packages("h2o")
libary(h2o)
h2o.init(nthreads=-1)
h2o Modell erstellen und testen
data<-h2o.importFile("userjourney.txt") // Einlesen des User-Journeys
datasplit<-h2o.splitFrame(data,0.7)
modell<-parts[[0]]
validation<-parts[[1]]
y<-C5
x<-setdiff(names(modell), y)
m<-h2o.deeplearning(x,y,modell) // Erstellt das Modell
h2o.performance(m, test) // Testet die Vorhersage gegen die Testdaten
(Quellcode basierend / mehr Informationen: https://www.rdocumentation.org/packages/h2o/versions/3.24.0.5/topics/h2o.deeplearning )
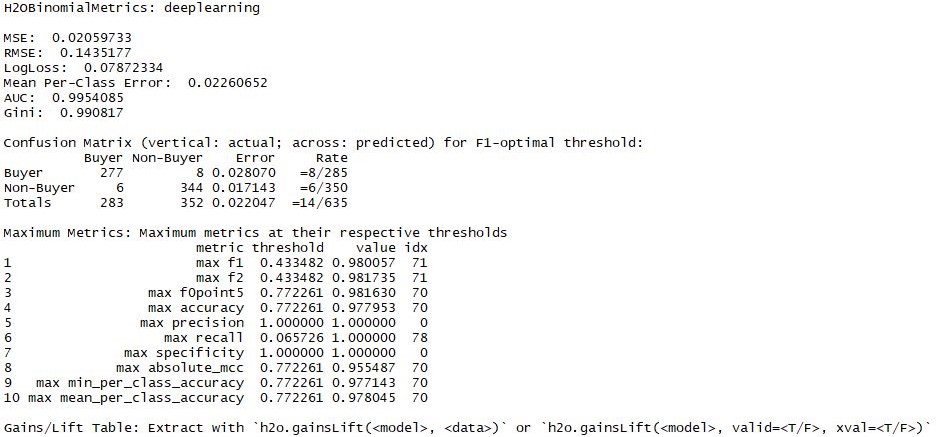
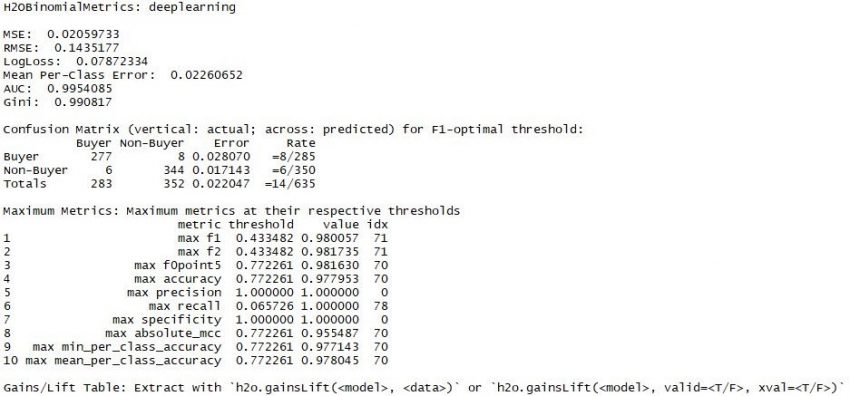
Vorhersage der „next best activity“
Auch wenn das Modell nicht alles richtig vorhersagt, ist die Abweichugn doch vertretbar.

Daher wollen wir es nutzen, um bei einer konkreten User-Journey mit 3 Kontaktpunkten die „next best activity“ vorherzusagen. Dafür nehmen wir die bisherige User-Journey und reichern diese um den 4 Kontaktpunkt an. Natürlich können wir nicht jeden Kontaktpunkte kontrollieren. Beispielsweise bringt der Kontaktpunkt Display als Vorhersage nicht viel, da es nicht unserer Kontrolle unterliegt, ob genau dieser User die Anzeige beim surfen sieht. Nehmen wir also an, die folgenden Kontaktpunkte können kontrolliert werden:
- Newsletter
- Mailing
- Search
- Voucher
Hierfür wird ein Dataframe erstellt, der alle Kombinationen der bisherigen User-Journey und der kontrollierbaren Kontaktpunkte enthält, also
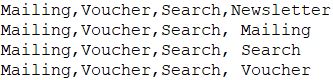
Dieses wird als CSV Datei eingelesen:
datapred<-h2o.importFile("uj-prediction.txt")
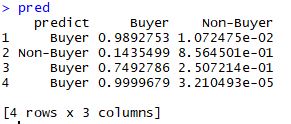
pred<-h2o.predict(m, datapred) // Vorhersage mit dem Modell m
Das Ergebnis zeigt, das ein Mailing ungeeignet ist und der Voucher mit der höchsten Wahrscheinlichkeit dazu führen kann, das ein User nach dem 4. Kontaktpunkt kauft.
Fazit
Dieses oberflächliche Detail ist ein erster Schritt um das Zusammenspiel von Marketing-Kanäle nicht nur zu analysieren, sondern aktiv diese auf individueller User-Journey Basis zu gestalten. Im nächsten Teil wird dieses Modell verfeinert.
1 thought on “h2o Machine Learning: Individuelle Vorhersage für die „next best activity“ – Teil 1”
Comments are closed.