Seit der Notwendigkeit von Cookie Bannern im Web ist ein Thema sehr populär geworden: “cookieless tracking”. Unter dem Begriff “cookieless tracking” wird meist nicht nur die Vermeidung von Cookies, sondern allgemeiner die Vermeidung der Speicherung von Informationen im Endgerät (hier meist ein Browser) verstanden. Denn egal ob Daten in Cookies, Local Storage, Session Storage, etc. gespeichert werden, eine Zustimmung des Nutzers ist erforderlich, sofern diese nicht technisch notwendig sind. Das heißt, dass die Identifier, die in der Webanalyse verwendet werden, um den User (eigentlich Browser des Users) wiederzuerkennen und Metriken zweiten Grades wie Sessions und User zu berechnen entweder im Endgerät des User speichern können oder irgendwoher andere Identifier bekommen, die nicht im Endgerät gespeichert werden. Ein sehr weit verbreiteter Ansatz ist hier die Verwendung von IP-Adresse, User-Agent und gegebenenfalls anderen Daten, wie Datum, das dann als gehashter Wert verwendet wird. Mit dem Identifier ist eine Erfassung der User ohne Zustimmung wohl möglich, da keiner der verwendeten Werte aus dem Endgerät ausgelesen wird und schon beim Request bekannt sind. Doch auch dieses Vorgehen wird von Browserherstellern immer stärker torpediert. Im folgenden eine kleine Auswahl.
Wie funktioniert das Tracking mit First-Party-Cookies?
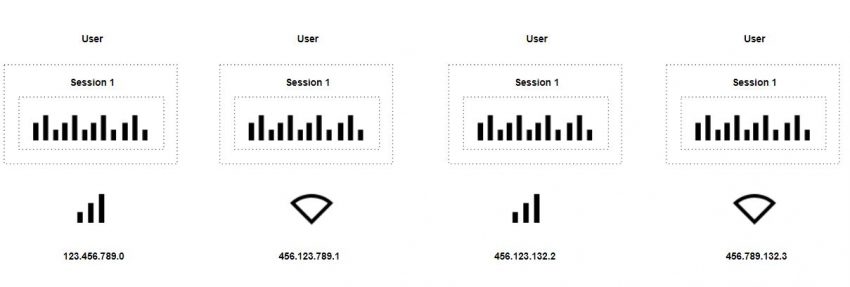
Kommt ein User das erste Mal auf eine Webseite, wird ein First-Party-Cookies im Browser des Users gespeichert, das eine eindeutige ID und gegebenenfalls weitere Informationen enthält. Mit jeder Information an das Webanalyse Tool wird diese ID mitgesendet. Dadurch entstehen Metriken ersten Grades wie Pageviews, Events, etc.
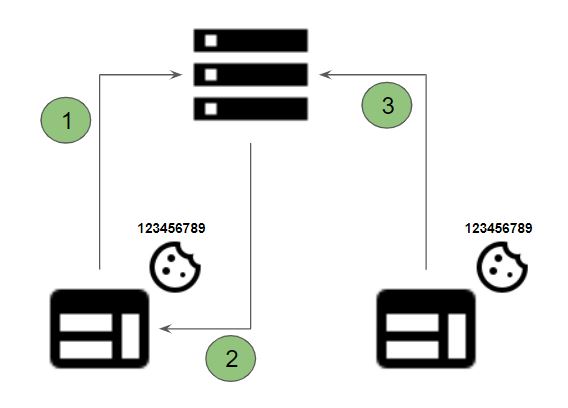
Die einzelnen Informationen werden dann zu Metriken zweiten Grades verkettet, wie Sessions, Users, etc.
Voraussetzung dabei ist allerdings, das das Cookie dabei nicht gelöscht wird. First-Party-Cookies können nicht nur vom Nutzer gelöscht werden, sondern werden auch von Browsern mehr eingeschränkt. Safari und alle Browser auf iOS begrenzen mit ITP die Laufzeit von clientseitig gesetzen Cookie auf 7 Tage, Firefox auf 45 Tage und auch für Chrome gibt es einen Draft für Version 102, der Cookies auf maximal 400 Tage begrenzen soll: https://chromestatus.com/feature/4887741241229312.
Hinzu kommt, das durch die Einwilligungspflicht viele Besucher auf der Seite nicht erfasst werden. Zustimmungsraten sind recht unterschiedlich von Seite zu Seite.
Auch wenn durch serverseitiges Setzen der Cookies und andere Maßnahmen die Auswirkungenen auf die Datenqualität und Datenqualität abgemildert werden können, so verlockend klingt die Aussicht, alle Daten zu erfassen, indem “cookieless” getracked wird.
Cookieless Tracking
Auch beim Cookieless Tracking wird ein Identifier benötigt, der mit jeder Information mitgesendet wird. Die Funktionsweise des Webanalyse Tools wird dadurch normalerweise nicht beeinflusst. Das heißt für Metriken ersten Grades spielt es bei der Verarbeitung erstmal keine Rolle, ob die Daten Cookieless oder mit Cookie erhoben werden. Die Anzahl der Events oder Pageviews ist mit Cookie Identifier oder Cookieless Identifier gleich, sofern diese aus dem Browser gesendet werden. Allerdings benötige ich für den Cookie Identifier eine Zustimmung, für den cookieless Identifier wohl nicht. Wodurch sich die Datenquanität bei beiden Ansätzen je nach Zustimmungsrate deutlich unterscheidet. Insofern werden cookieless nahezu (natürlich greifen Adblocker etc.) alle Informationen zu Metriken ersten Grades erhoben, bei Cookie Identifiern nur die Informationen bei denen einen Zustimmung vorliegt. Allerdings gibt es bei Ansätzen, die auf IP-Adresse und User-Agent beruhen, durchaus Schwachstellen in der Datenqualität. Ich stelle im Folgenden eine Beispiele dar, wie die Generierung eines Hashes aus IP-Adresse, User-Agent und gegebenenfalls weiterer Informationen die Datenqualität beeinflussen können.
Kurzlebiger Identifier IP-Adresse
Die IP-Adresse ist ein kurzlebiger Identifier und ändert sich pro Gerät häufig. Das ist beim cookieless Tracking häufig sogar gewollt, damit User nur in einem vordefinierten Zeitfenster wiedererkannt werden können. Beim cookieless Einsatz von Matomo wird beispielsweise explizit ein Zeitfenster von bis zu 24 Stunden genannt, in der der Identifier gültig ist (https://matomo.org/faq/general/how-is-the-visitor-config_id-processed/).
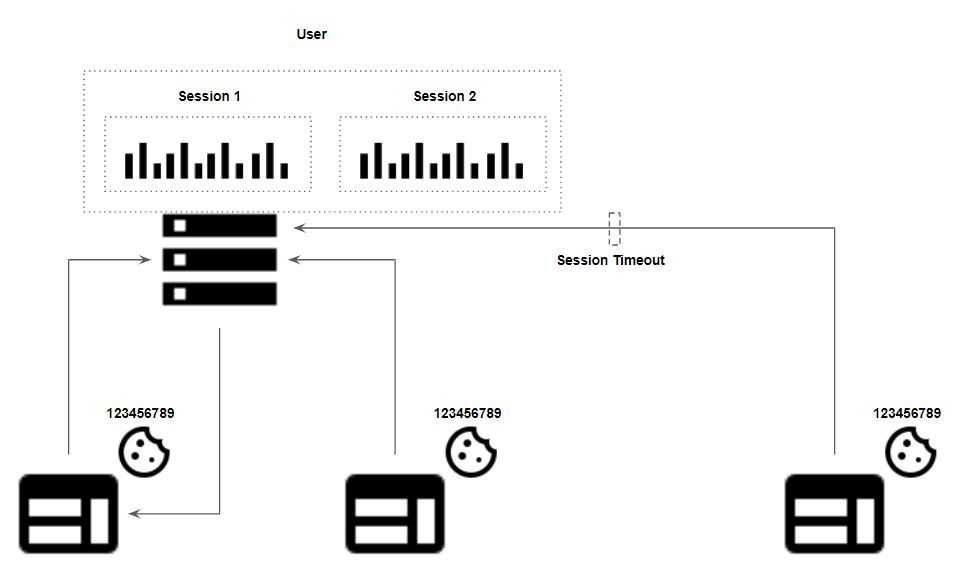
Somit sind User Auswertungen und darauf basierende Metriken wie Sessions / Users bei einem cookieless tracking meist nicht wirklich sinnvoll. Ebenso ist Attribution und User-Journey Tracking auf die Haltbarkeit des Identifiers begrenzt. Allerdings können auch andere Metriken davon beeinflusst werden, beispielsweise Sessions. Ein Beispiel:
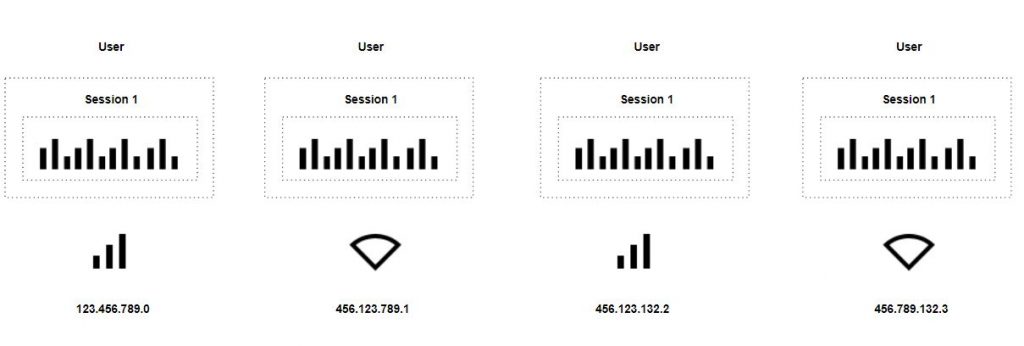
Ein User nutzt die Webseite mobil über verschiedene Stationen hinweg. Zuerst wird eine Session generiert, mit der IP Adresse generiert, die dem User mobil zugewiesen wurde. Im zweiten Schritt nutzt der User das öffentlich angebotene Wifi. Dadurch ändert sich die IP Adresse und der User öffnet eine weitere Session wenn eine Information an das Webanalyse Tool gesendet wird. Im dritten Schritt nutzt der User wieder seine mobil zugewiesene IP Adresse. Ist der Timeout der ersten Session bereits erreicht, wird eine neue Session eröffnet. Falls der Timeout noch nicht erreicht, wird die gesendete Information mit der Information aus Schritt zu einer Session zusammengefasst, Im vierten Schritt verbindet sich das Gerät mit einem anderen Wifi und der User öffnet eine weitere Session wenn eine Information an das Webanalyse Tool gesendet wird.
Der gleiche Nutzer hätte somit 3 bis 4 Sessions und damit auch User generiert. Bei einem Einsatz von First-Party Cookies bei entsprechender Zustimmung werden die Informationen zu einer Session verkettet.
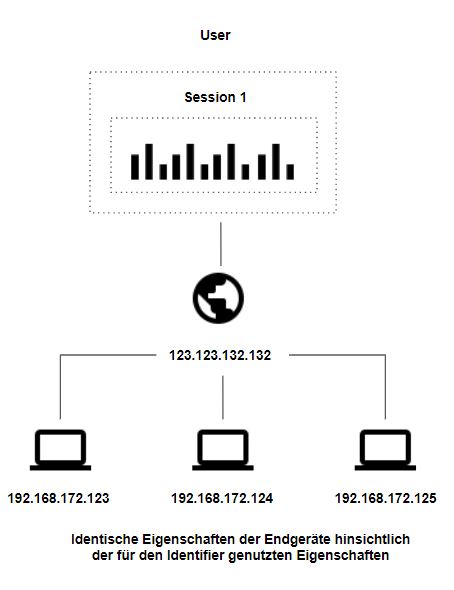
Request IP-Adresse identifiziert kein Gerät
Ein gegenteiligen Effekt ergibt sich durch Netzwerke, die in der Kommunikation gegenüber dem Server eine IP angeben unabhängig davon, wieviel Endgeräte sich wirklich hinter dem Netzwerk verbergen. In einem Firmennetzwerk wird beispielsweise mehreren Endgeräte mit dem gleichen Eigenschaften, die für den Identifier verhasht werden, der gleiche Identifier zugewiesen. Somit werden Metriken ersten Grades mehrerer Endgeräte dem gleichen User, und wenn dies innerhalb des Session-Timeout passiert, der gleichen Session, zugeordnet. Die Auswirkungen auf die Datenqualität hängt natürlich enorm von der Größe des Netzwerk ab, hinter dem sich die Endgeräte befinden.
IP-Adresse auf iOS15
Mit Safari 15 werden die aufgezeigten Auswirkungen noch größer. Denn auf Endgeräten mit Safari 15 wird die IP Adresse verborgen, wenn der Tracker im DuckDuck Go Tracker Radar auftaucht(https://github.com/duckduckgo/tracker-radar, https://www.cookiestatus.com/safari/).
Einschränkungen beim User-Agent
Auch beim User-Agent gibt es Einschränkungen. Der User Agent identifiziert den Browser und die Browserversion. Fließt die Information in den Identfiier ein, wird es dadurch möglich, die Anzahl der Endgeräte einzuschränken, die sich hinter einer IP “verbergen”. Alle nicht passenden User Agents werden also ausgeschlossen. Durch die Nutzung von Browser Versionsnummer bis auf Minor Versions heruntergebrochen, kann unter Umständen eine recht granulare Zuordnung möglich sein. Browserhersteller gehen dazu aber über, die Informationen im User-Agent stärker einzuschränken. Hier ein Beispiel in Chrome Version 100, wie der User Agent übermittelt wird:

Chrome 100 bietet ein Beta Feature, das die Reduktion des User Agents ermöglicht, das in zukünftigen Versionen Standard sein soll (Roadmap: https://blog.chromium.org/2021/09/user-agent-reduction-origin-trial-and-dates.html).

Die Minor Version des Browser ist mit 0.0.0 angegeben. Alle Chrome Versionen 100 unabhängig von der Minor Version identifizieren sich damit gleich (abgesehen von den anderen Informationen im User-Agent). Insofern wird damit auch der User-Agent ungenauer und damit auch die Datenqualität.
Einige Browser besitzen gar keinen eigenen User Agent. Brave beispielsweise identifiziert sich als Chrome Browser, wodurch die Verwässerung der Wiedererkennung zunimmt (Vielen Dank für den Hinweis Markus Baersch, der das Thema consentless auch in einem Artikel schon 2019 beleuchtet hat. Seitdem hat sich einiges getan, aber sehr lesenswert: https://www.markus-baersch.de/blog/herausforderungen-des-trackings-ohne-consent/)

Fazit
Auch wenn die Idee über IP Adresse und User Agent einen Identifier zu bilden und damit cookieless und consentless Daten zu erheben, so sind im Detail einige Fallstricke vorhanden, die die Datenqualität beeinflussen können. Insofern ist die Entscheidung ob cookiebasiert oder cookieless auch meist eine Abwägung zwischen höherer Datenqualität mit First Party Cookies zu höherer Datenquantität mit IP und User Agent Identifier.
Danke für das Update, spannend aktueller Follow-Up zu den Basisartikeln von Markus Baersch! Die Dynamik bleibt weiter im Spiel. Es macht auch Sinn Users und Sessions um die weitere Dimension Consent vs. Non-Consent zu ergänzen. Denn im Falle von Consent sollte die Kernwährung 1st-Party-Cookie für die KPI’s Users und Sessions weiter genutzt werden. Hingegen bei den Ablehnern fällt die KPI Users aus deinen o.g. Gründen weg, es bleiben nur noch die cookieless gemessenen Sessions samt Anhang wie Traffic-Quelle und Onsite-Aktivitäten. Diese Non-Consent-Daten, somit ohne Personenbezug cookieless erhobenen KPI’s sind individuell je nach Webseite statistisch kritisch gegen die KPI’s mit der Dimension Consent zu beobachten, um ihre Richtigkeit im Hinblick auf den Session-Identifier bewerten zu können.