Die Vielfalt der Features in Google Analytics 4 wächst stetig. Damit werden die Anwendungsfälle über das reine Messen von Events mit Event-Parametern und User-Properties deutlich spannender für die operative Umsetzung der Daten. Ein Beispiel hierfür ist die User Segmentierung und Nutzung für Audience Listen. In diesem GA4 Recipe zeige ich, wie mit GA4 in Kombination mit BigQuery User nach RFM (= Recency, Frequency, Monetary) klassifiziert und in GA4 genutzt werden können.
RFM: Modell und Datengenerierung
Das RFM Modell (auch RFM-Analyse) wird genutzt, um bestehende Kunden anhand von drei Dimensionen zu bewerten:
- Recency: Mit der Dimension Recency wird die Zeitspanne seit dem letzten Kauf beschrieben. Die Annahme bei dieser Dimension ist, das Kunden, die kürzlich gekauft haben, eine höhere Wahrscheinlichkeit für einen erneuten Kauf aufweisen
- Frequency: Die Dimension Frequency beschreibt die Häufigkeit von Käufen eines Kunden. Bei Kunden, die häufiger gekauft haben, kann auch in Zukunft von einem ähnlichen Verhalten ausgegangen werden.
- Monetary: Mit Monetary wird der Gesamtwert aller Käufe in der Vergangenheit in einer Dimension abgebildet.
In der “üblichen” Anwendung würde ein Klassifikation der Dimensionen vorgenommen, so das jeder User anhand dieser drei Kriterien in eine Klasse eingeordnet werden kann.
Mit dem BigQuery Export von GA4 können diese Daten einfach extrahiert werden. Zuerst werden alle Umsätze zu Käufen, die user_pseudo_id (als User-Merkmal) und der dazugehörige Timestamp in BigQuery gesucht:
SELECT event_timestamp, user_pseudo_id, ecommerce.purchase_revenue FROM `<Projekt>.<Dataset>.events_*` where event_name="purchase"
Das Ergebnis der Suche sieht wie folgt aus:
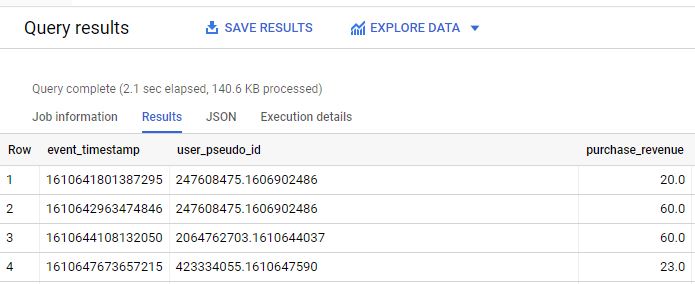
Mit diesen Daten können nun die Dimensionen extrahiert werden:
- Recency: Differenz des aktuelle Timestamp und dem Maximum des Timestamps nach User_pseudo_id. Das Ergebnis wird in Tage umgerechnet
- Frequency: Die Häufigkeit einer user_pseudo_id gibt in den Daten die Anzahl der Käufe wieder
- Monetary: Diese Wert ergibt sich aus der Summe des Revenues der Käufe pro user_pseudo_id.
Der Query sieht dann wie folgt aus:
WITH
R AS
(
SELECT
user_pseudo_id,
max(event_timestamp) as recency
from
(
SELECT event_timestamp, user_pseudo_id, ecommerce.purchase_revenue FROM `<Projekt>.<Dataset>.events_*` where event_name="purchase"
)
group by user_pseudo_id
),
FM as
(
SELECT
user_pseudo_id,
event_timestamp,
sum(IFNULL(purchase_revenue,0)) as CLV,
count(user_pseudo_id) as totalevents
from
(
SELECT event_timestamp, user_pseudo_id, ecommerce.purchase_revenue FROM `<Projekt>.<Dataset>.events_*` where event_name="purchase"
)
GROUP BY user_pseudo_id, event_timestamp
),
RFM AS
(
SELECT FM.user_pseudo_id, DATE(Timestamp_micros(R.recency)) as recency , FM.CLV as monetary FROM FM
JOIN R ON FM.user_pseudo_id=R.user_pseudo_id
)
select
DATE_DIFF(current_date(),recency,day) as recency,
count(user_pseudo_id) as frequency,
sum(monetary) as monetary,
user_pseudo_id
from RFM
group by user_pseudo_id,recencyDas Ergebnis des Queries:
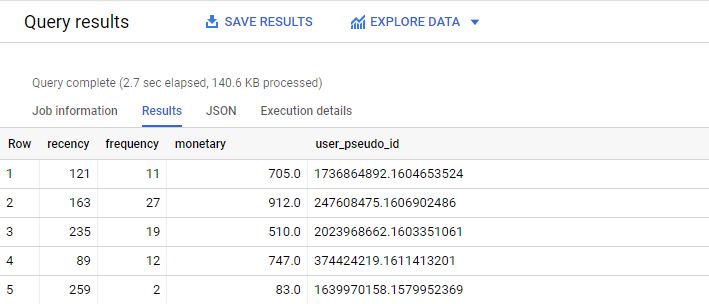
Die Daten werden nun als Table, hier RFM genannt, gespeichert.
Clustering der Daten mit K-Means (BQML):
Um die Daten zu segmentieren, bietet sich an, K-Means direkt in BigQuery zu nutzen. K-Means ist ein Verfahren, bei den anhand der Eingabe-Dimensionen Gruppen nach Ähnlichkeiten gebildet werden. In diesem Fall sind die Eingabe-Dimensionen die Werte Recency, Frequency, Monetary. Die Anzahl der über K-Means zu bildenden Gruppen wird im Vorfeld festgelegt. Der Algorithmus bestimmt Clusterzentren, die eine Zuweisung einer Dimensions-Kombination aufgrund der kleinsten euklidischen Distanz zu einem der Clusterzentren erlaubt. Dadurch entsteht die Ähnlichkeit der Dimensionskombinationen eines Clusterzentrums.
Auch wenn K-Means einige Schwachstellen hat, ist für diesen Anwendungsfall der große Vorteil, das K-Means eines der von BigQuery Machine Learning unterstützen Verfahren ist. Insofern kann direkt in BigQuery ein Modell mit K-Means erstellt werden. Mit einem Query werden die Eingabedimensionen definiert und das Modell trainiert:
CREATE OR REPLACE MODEL `<Projekt>.<Dataset>.RFM_kmeans` OPTIONS(
model_type='kmeans',
num_clusters=3,
standardize_features = true
) AS
select * except (user_pseudo_id) from `<Projekt>.<Dataset>.RFM`Hier werden drei Cluster verwendet. Das Ergebnis des Modells:
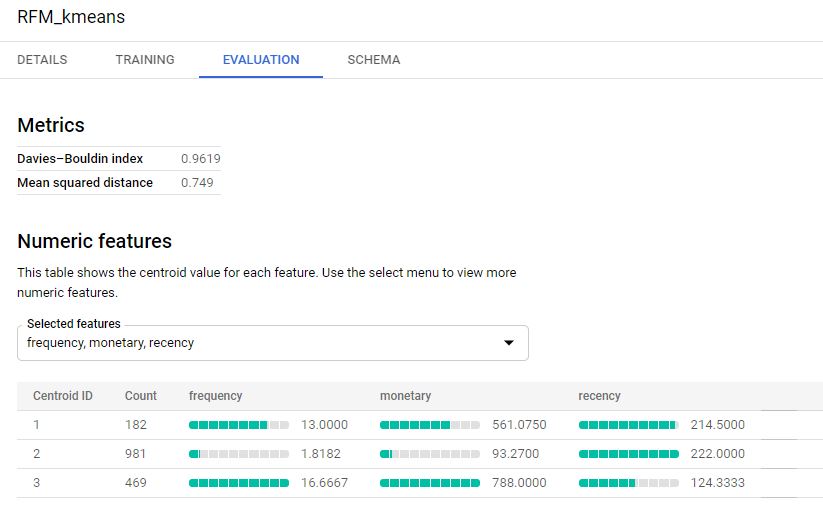
Es wurden drei unterschiedliche Clustereinteilungen generiert. Nachdem das Modell aus den Daten generiert wurde, wird es auf die Daten erneut angewendet, allerdings nicht zum Training, sondern zum Clustering. Das Ergebnis ist die Zuordnung einer user_pseudo_id zu einem Cluster:
select CENTROID_ID as Cluster, user_pseudo_id
FROM ML.PREDICT(MODEL ``<Projekt>.<Dataset>.RFM_kmeans`,
(
select * from ``<Projekt>.<Dataset>.RFM`)
)Das Ergebnis des Queries ist eine Kombination von user_pseudo_id und des Clusternamens:
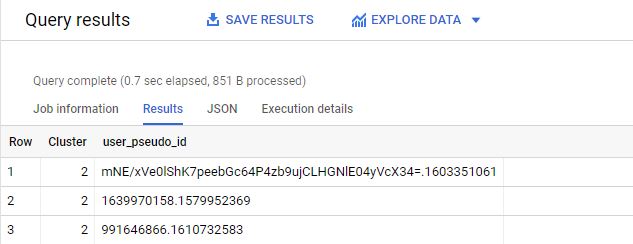
Datenimport nach GA4
Nachdem nun das Modell auf die EIngabedaten angewendet wurde, können die Daten per Datenimport nach GA4 hochgeladen werden (eine API ist zu diesem Zeitpunkt noch nicht verfügbar).
Hierfür ist ein einfaches Format vorgesehen, bestehend aus user_pseudo_id, stream_id (ID des Datastreams) und dem Wert der User Property:
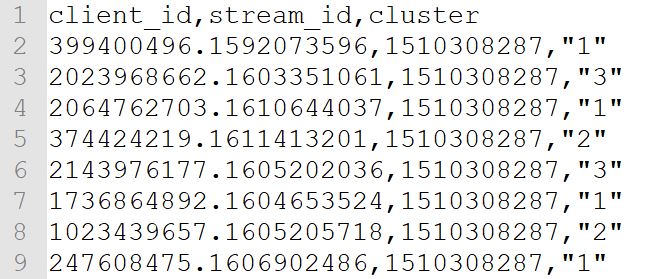
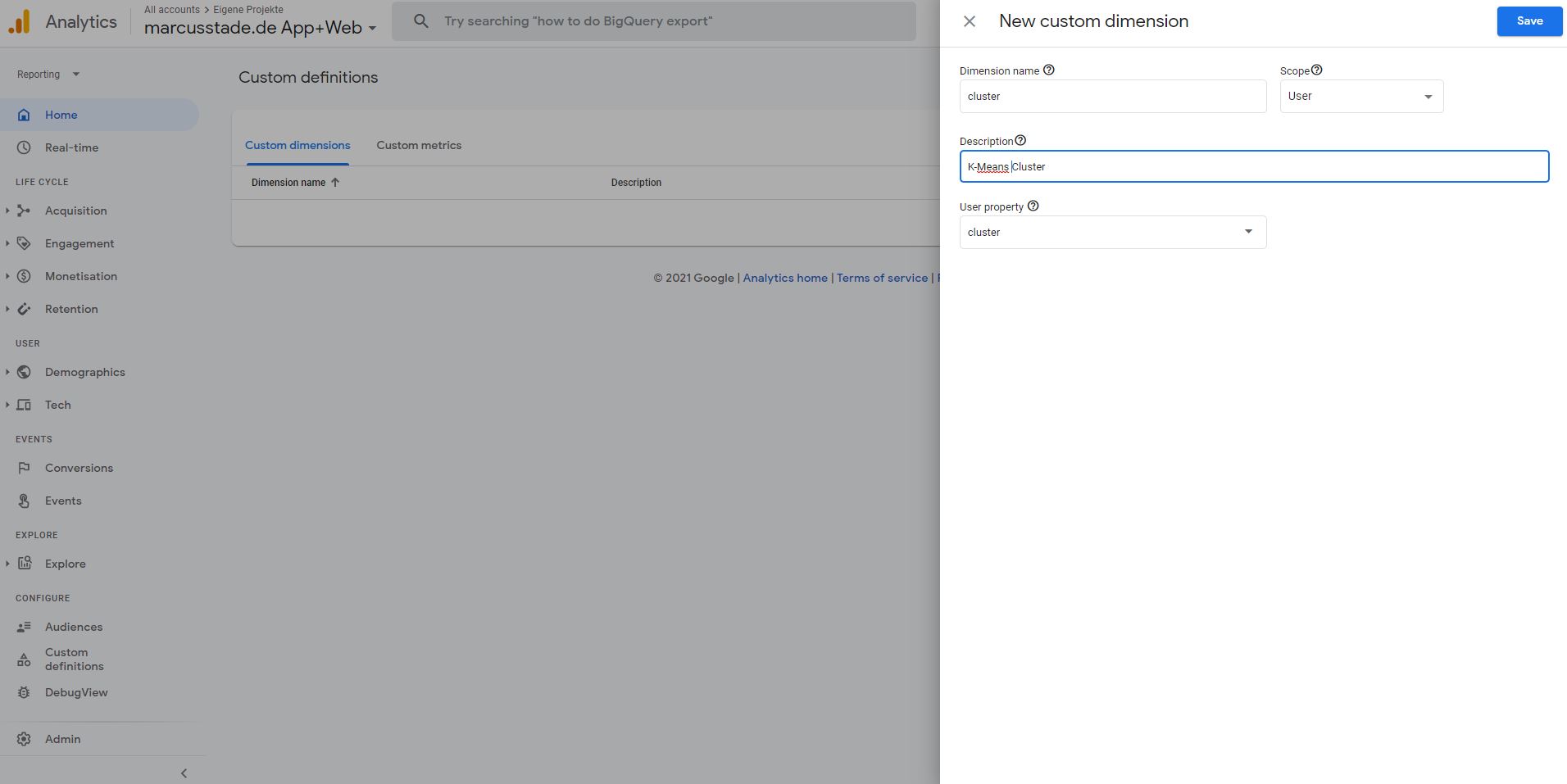
Zuerst wird im Menü Custom Dimensions die User Property (Custom Dimension User Scope) registriert:
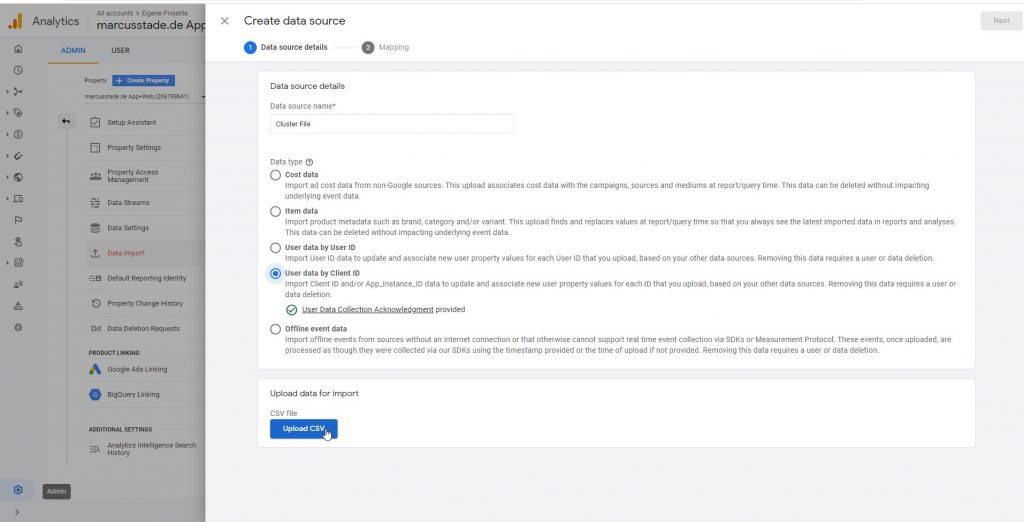
Dann kann der Datenimport konfiguriert werden:
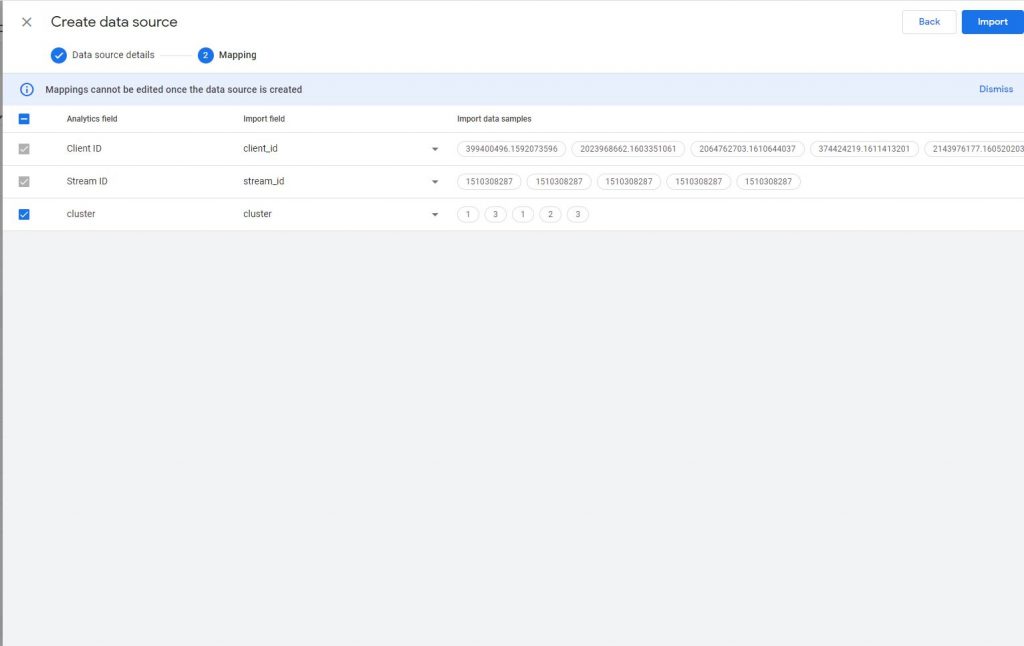
und die Daten gemapped werden:
Kommt der Nutzer das nächste Mal nach der Verarbeitung auf die Webseite, wird der Wert zugewiesen:
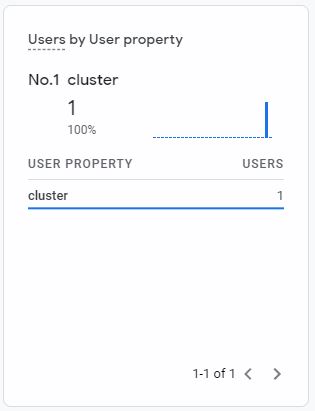
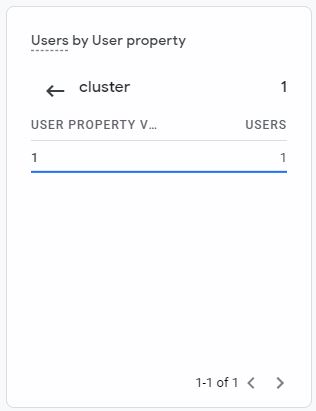
Und es können bspw. Audience Listen auf Basis der Custom Dimension gebaut werden:
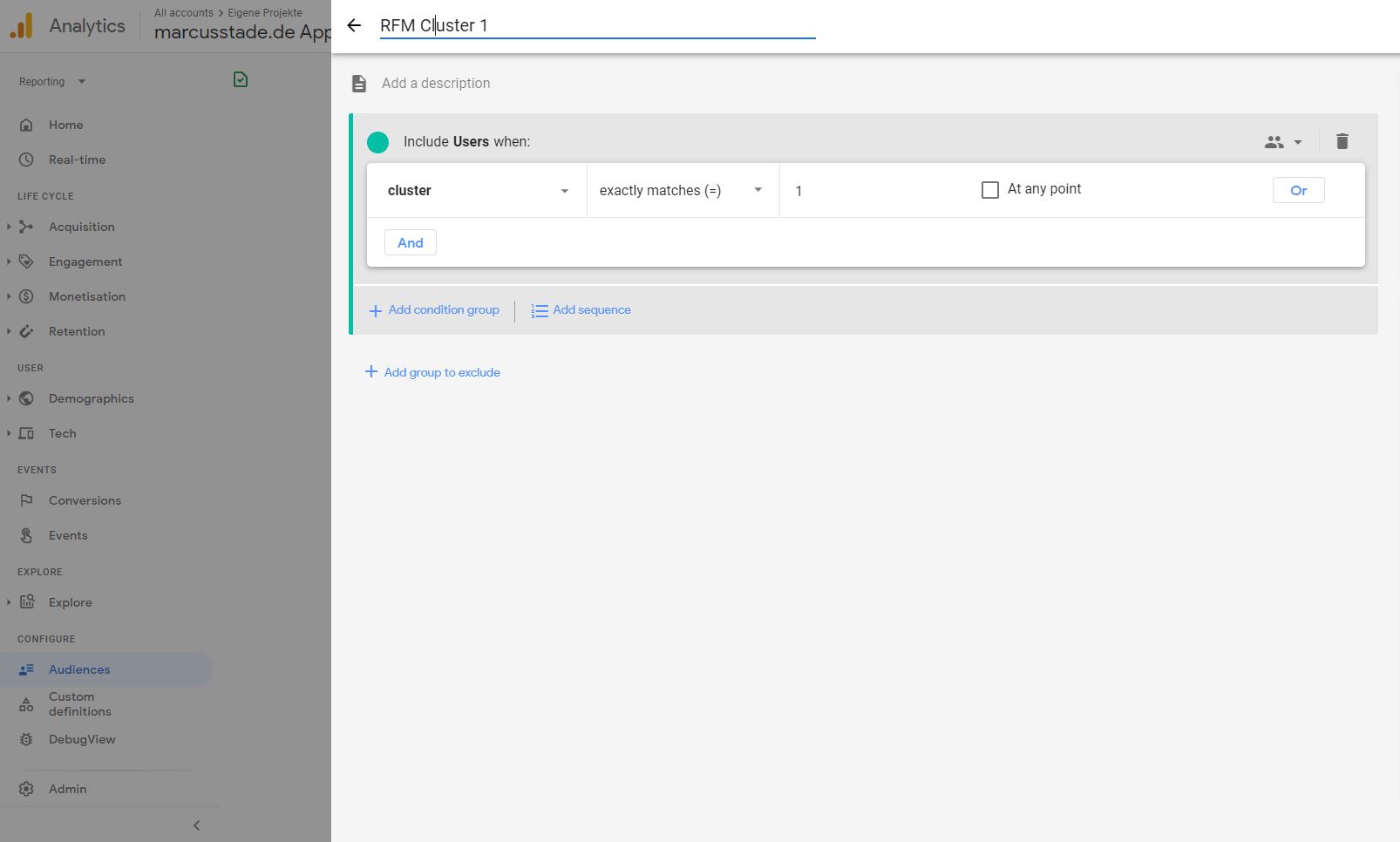
Realtime Integration
Anstatt die Daten in GA4 hochzuladen, ist natürlich auch eine clientseitige oder serverseitige Integration möglich. Da diese eine relativ kurze Antwortzeit voraussetzt und zudem die für die RFM Berechnung zu durchsuchende Datenmenge in BigQuery reduziert werden sollte, da der Query für jede Anfrage erneut generiert wird, ist eine tägliche Berechnung und Ablage in einem Table mit Hilfe von “Scheduled Queries” sinnvoll. Dafür wird der oben gezeigte Query einfach als “Scheduled Query” mit täglicher Ausführung angelegt, so das dieser den Table “RFM” jeden Tag überschreibt:
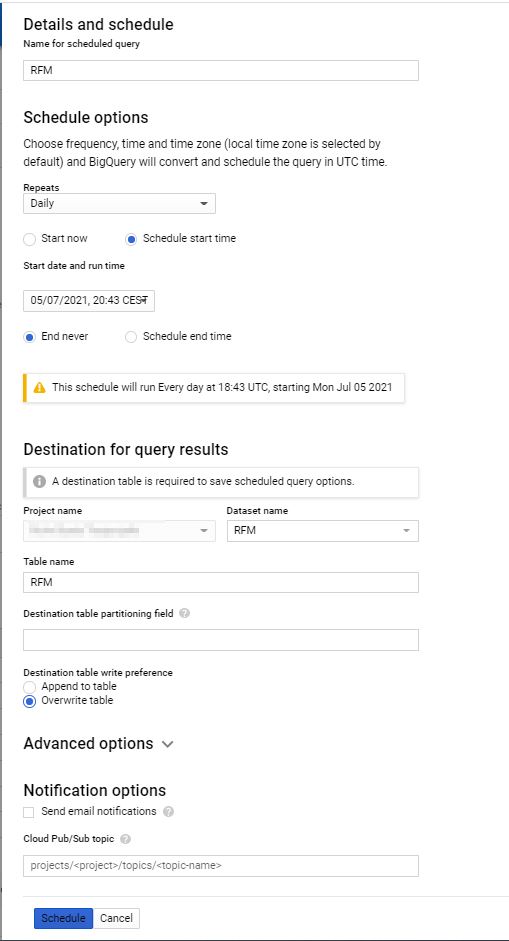
Da nun die notwendigen Daten bereits fertig aufbereitet sind, kann nun die eigentliche Integration clientseitig oder/und serverseitig erfolgen. Diese unterscheidet sich nur in der Rückgabe des Wertes als Rückgabewert der Cloud Function oder direkt als Measurement Protocol Hit nach GA4.
Bei der Integration wird die aktuelle user_pseudo_id per GTM an eine Cloud Function gesendet:
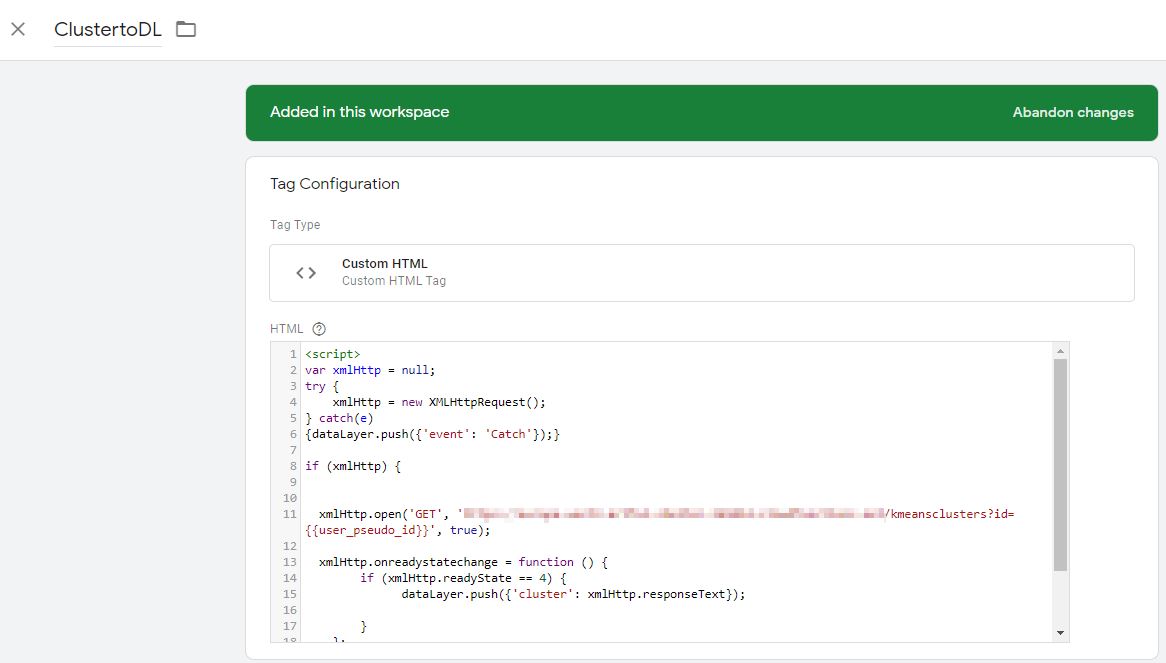
Die Cloud Function durchsucht den vorher generierten Table “RFM” und gibt die Werte für die user_pseudo_id zurück und diese Werte werden mit dem generierter Modell für ein Clustering angewendet::
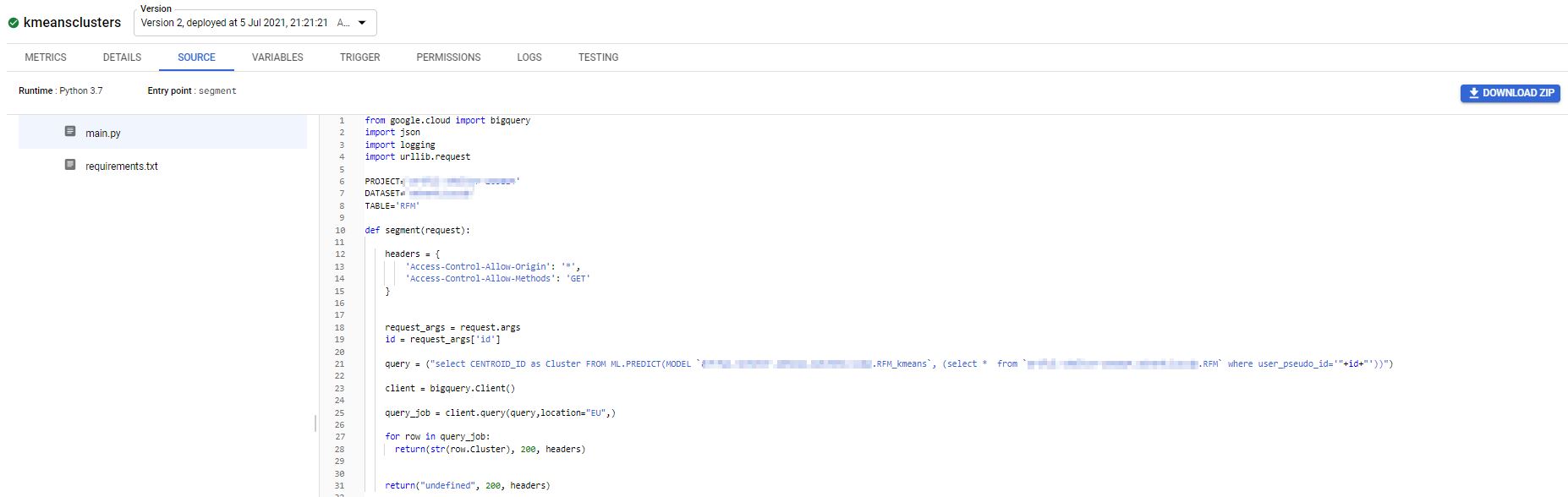
Das Ergebnis kann nur per MeasurementProtocol Hit nach GA4 gesendet werden (serverseitg, siehe https://www.marcusstade.de/google-analytics-4-recipes-measurement-protocol/) und/oder als Response der Cloud Function ausgegeben werden. Im oben gezeigten Tag wird das Ergebnis in den dataLayer geschrieben.
Das Ergebnis im dataLayer:
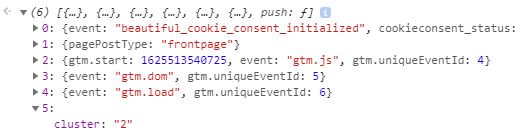
Da eine User Scope Custom Dimension genutzt wird, ist ein Mechnanis über Cookies u.ä. sinnvoll, um ein Update des Wertes nicht ständig zu triggern.
1 thought on “GA4 Recipes: User Segmentierung (RFM) mit BigQuery Export”
Comments are closed.